(四)深度学习之反向传播
(四)深度学习之反向传播
我们使用网络结构来构建模型,使得模型能够拟合复杂的现实问题,但是也产生了权重偏置更新开销巨大的问题。下文介绍反向传播的调参思想。
1. 反向传播
反向传播(backward propagation或backpropagation)指的是计算神经网络参数梯度的方法。简言之,该方法根据微积分中的链式规则,按相反的顺序从输出层到输入层遍历网络。
1.1 链式法则
已知二元函数 $z(x,y) = f(u,v)$, $u,v$ 又分别是 $x,y$ 的函数,则 $z$ 最终是 $x,y$ 的函数: $z(x,y) = f(u(x,y),v(x,y))$
$z$ 的全微分形式是:
又因为$u,v$是$x,y$的函数, 可以得到$z$关于$x,y$的全微分关系:
最后根据偏导数的定义就得到了:
1.2 误差反向传播
要想更新权重和偏置,最简单的方法就是 梯度下降法 (见篇(二)),也就是说,我们只需要求得 $L$ 对 $w,b$ 的偏导数就可以更新参数。
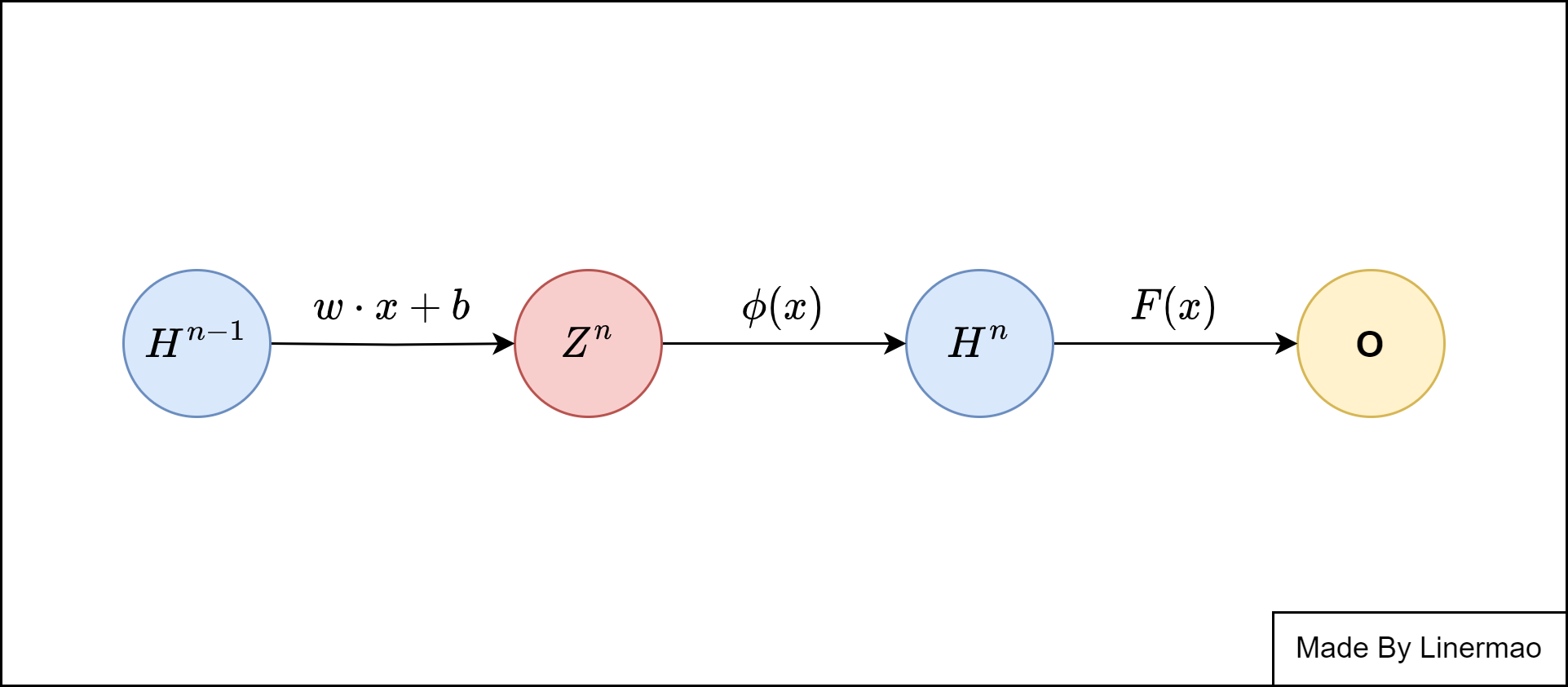
图2-1
我们先来规定几个变量的意义与写法:
接下来我们正式开始推导,我们先从输出层和最后一层隐藏层开始推导,根据我们的定义,我们可以得到:
我们有链式法则:
所以得到了:
目标函数 $J$ 对于 $b$ 的偏导不变,对于 $w$ 的偏导还需要加上正则项的导数形式,即:
综合以上,我们就得到了目标函数关于权重与偏置的梯度:
但是任务还没完成,上面的推导仅仅是 $n$ 取最后一层时的结果,还没有推导出递推项,所以我们可以继续推导:
整理一下,我们就得到了一个完整的公式:
写的简洁一点就是:
然后再使用梯度下降的方法就可以实现权重和偏置的更新。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 Linermao's kiosk!
