Transformer_PaperRead
Transformer Paper Read
Preface
This article is written to introduce the paper - ‘Attention is all you need’.
1. Attention is all you need
The google team use “Attention is all you need” as the title of transformer model, it break traditional network, not use conversation block but attention block, let me try to explain what is attention.
2. Structure
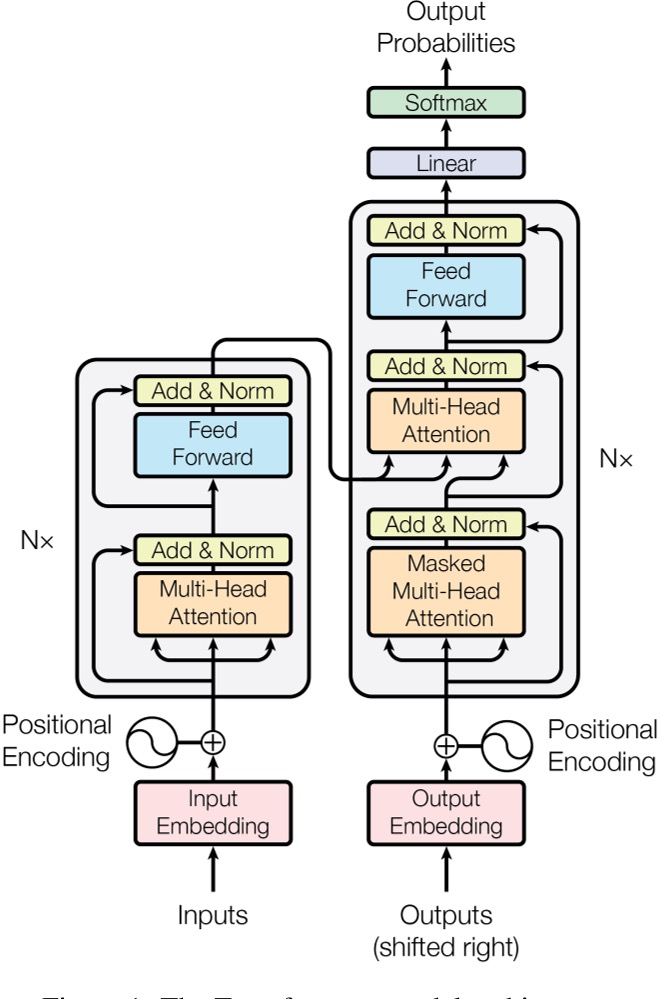
Figure-1 Structure (source: from paper)
What we need to pay attention to are Position Encoding and “the two blocks”.
Firstly, let’s focus on the “small block” - Encoder Block.
2.1 Multi-Head Attention Layer
In this part, the most puzzling is the “Multi-Head Attention Layer”.
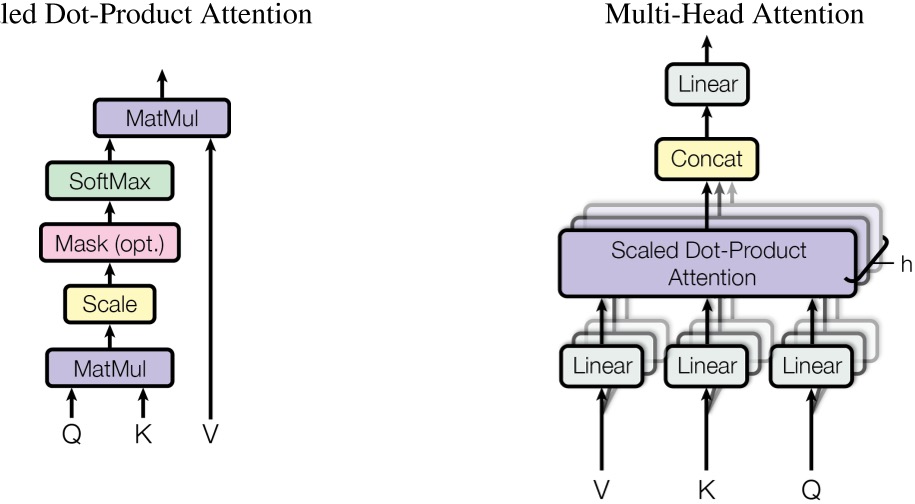
Figure-2 Multi Head (source: from paper)
Let’s start by looking at the single Attention Layer.
It’s mathematical formula is (Ignore Mask-layer):
So the Multi-Head Attention Layer is just combine N x single Attention Layer.
Before we device $ Q,K,V $, we define split weight $W^Q,W^K,W^V$.
It’s mathematical formula is:
2.2 Encoder Block
2.2.1 Add & Norm Layer
This layer corresponds to a residual network block, where the formula is:
$LayerNorm()$ is a function that normalizes data to accelerate calculations.
By use pytorch, we can use $torch.nn.LayerNorm()$ to use it.
2.2.2 Feed Forward Layer
This is a forward layer that simply uses the ReLU activation function, where the formula is:
$Linear()$ is a function that fully connected layers through linear change.
By use pytorch, we can use $torch.nn.Linear()$ to use it.
2.3 Decoder Block
The only difference between Decoder and Encoder is the Mask.
Why Mask is used?
This masking, combined with fact that the output embeddings are offset by one position, ensures that the predictions for position $i$ can depend only on the known outputs at positions less than $i$.
The simple fact is that because the inputs are sequentially related, we need to preserve the sequential relationship of the inputs.
The code section will describes how to create a Mask.
2.4 Positional Encoder
What is Positional Encoder?
Since our model contains no recurrence and no convolution, in order for the model to make use of the order of the sequence, we must inject some information about the relative or absolute position of the tokens in the sequence. To this end, we add “positional encodings” to the input embeddings at the bottoms of the encoder and decoder stacks. The positional encodings have the same dimension dmodelas the embeddings, so that the two can be summed. There are many choices of positional encodings, learned and fixed.
In languages, the order of the words and their position in a sentence really matters. The meaning of the entire sentence can change if the words are re-ordered. When implementing NLP solutions, recurrent neural networks have an inbuilt mechanism that deals with the order of sequences. The transformer model, however, does not use recurrence or convolution and treats each data point as independent of the other. Hence, positional information is added to the model explicitly to retain the information regarding the order of words in a sentence. Positional encoding is the scheme through which the knowledge of the order of objects in a sequence is maintained.
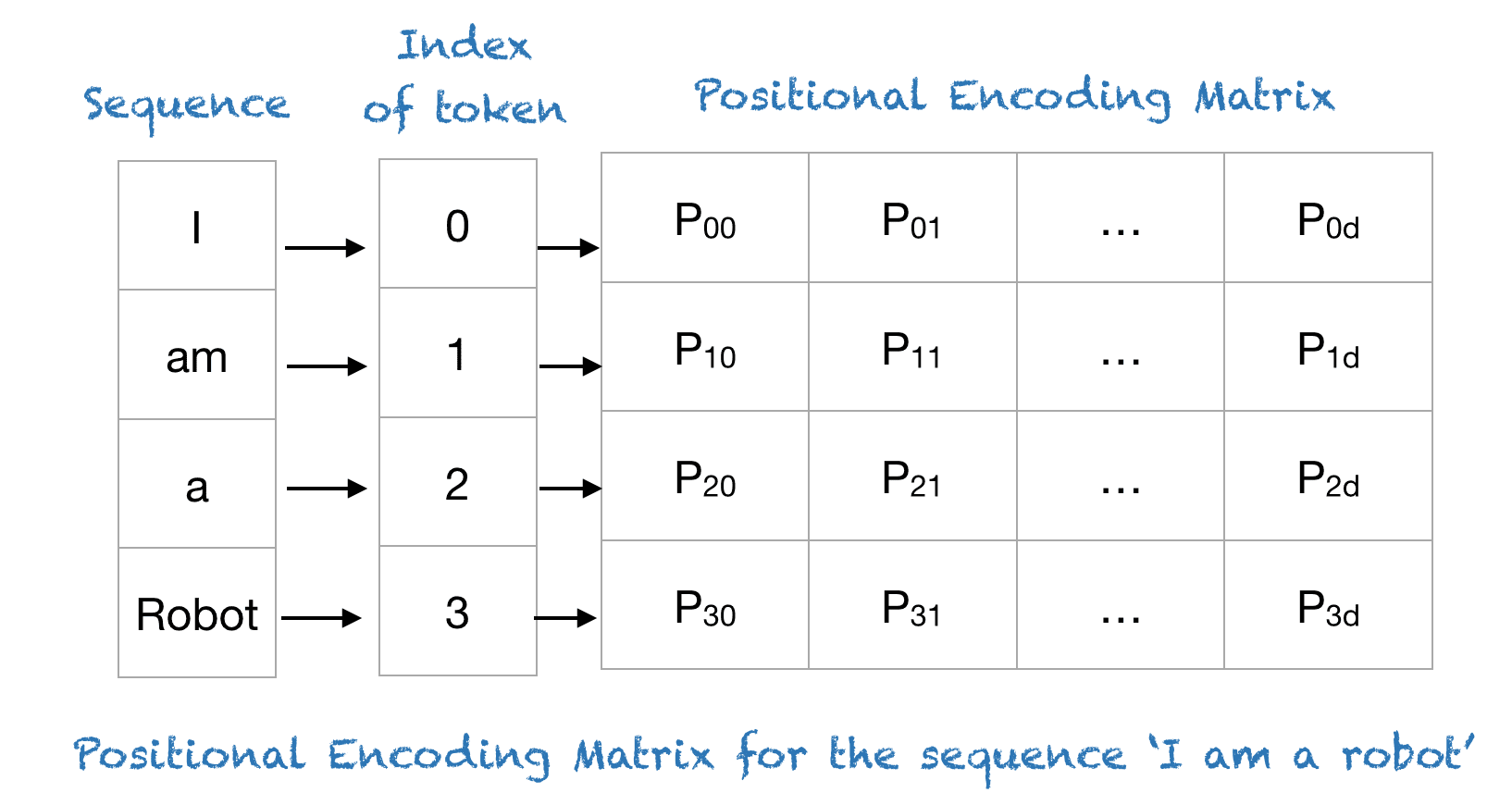
Figure-3 Positional Encoding (source: from machinelearningmastery.com)
The smart positional encoding scheme, where each position/index is mapped to a vector. Hence, the output of the positional encoding layer is a matrix, where each row of the matrix represents an encoded object of the sequence summed with its positional information. An example of the matrix that encodes only the positional information is shown in the figure below.
In paper, the team use following formula:
$pos$ is the position and $i$ is the dimension.
Here is an example:
Figure-4 Example (source: from machinelearningmastery.com)
By using location coding, we can then transform data positional information into low to high frequency information.

Figure-4 Example (source: from machinelearningmastery.com)
3. Meaning
The proposed Transformer model breaks the dominance of traditional Recurrent Neural Networks (RNN) and Convolutional Neural Networks (CNN) in natural language processing.Transformer is able to capture the relationship between any two elements of an input sequence regardless of their position, through the introduction of self-attention, which is difficult for RNN and CNN to achieve. position, which is difficult to achieve with RNN and CNN.
Because of the emergence of Transformers, more big models are abandoning the traditional CNN and RNN structures and achieving breakthrough results on more tasks.
