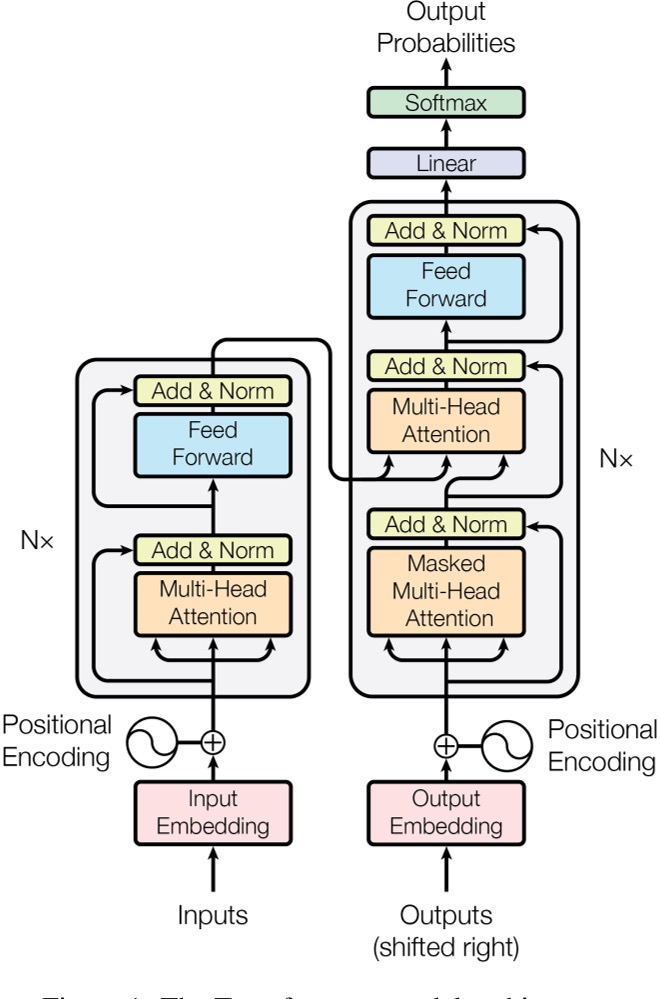
Since I am also still learning, each subsection also explains the usage and role of some functions.
1. Multi-Head Attention Layer
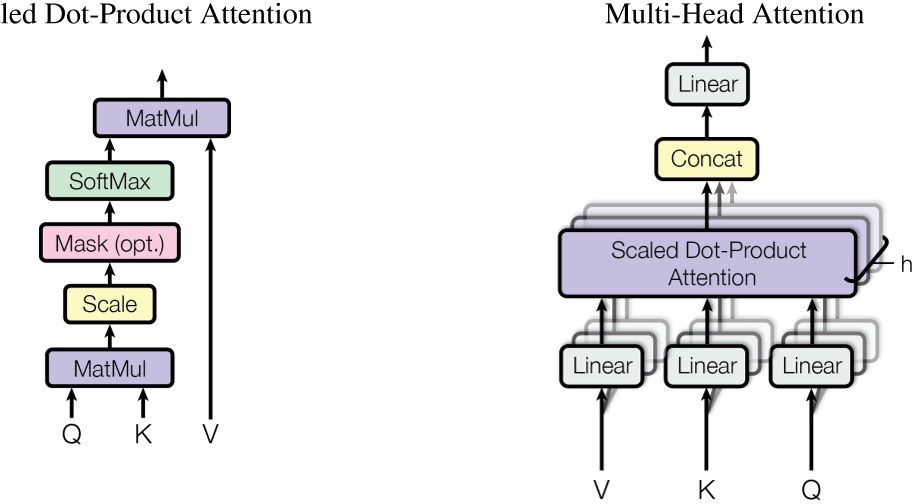
Figure-1 Multi Head (source: from paper)
Firstly, let us focus on implementing “single-attention”.
The formula is:
Full Code
classMultiHeadAttention(nn.Module): ''' scaled_dot_product_attention(self, Q, K, V, mask=None): Calculate self-attention value split_heads(self, x): Reshape the input to have num_heads for multi-head attention combine_heads(self, x): Combine the multiple heads back to original shape forward(self, Q, K, V, mask=None) '''
def__init__(self, d_model, num_heads): ''' d_model: Dimensionality of the input num_heads: Number of attention heads d_k: Dimension of each head's key, query, and value '''
super(MultiHeadAttention, self).__init__() # Ensure that the model dimension (d_model) is divisible by the number of heads assert d_model % num_heads == 0, "d_model must be divisible by num_heads" # Initialize dimensions self.d_model = d_model self.num_heads = num_heads self.d_k = d_model // num_heads # Linear layers for transforming inputs self.W_q = nn.Linear(d_model, d_model) self.W_k = nn.Linear(d_model, d_model) self.W_v = nn.Linear(d_model, d_model) self.W_o = nn.Linear(d_model, d_model) defscaled_dot_product_attention(self, Q, K, V, mask=None): # Calculate self-attention scores attn_scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(self.d_k) # Apply mask if provided (useful for preventing attention to certain parts like padding) if mask isnotNone: attn_scores = attn_scores.masked_fill(mask == 0, -1e9) # Softmax is applied to obtain attention probabilities attn_probs = torch.softmax(attn_scores, dim=-1) # Multiply by values to obtain the final output output = torch.matmul(attn_probs, V) return output defsplit_heads(self, x): # Reshape the input to have num_heads for multi-head attention batch_size, seq_length, d_model = x.size() return x.view(batch_size, seq_length, self.num_heads, self.d_k).transpose(1, 2) defcombine_heads(self, x): # Combine the multiple heads back to original shape batch_size, _, seq_length, d_k = x.size() return x.transpose(1, 2).contiguous().view(batch_size, seq_length, self.d_model) defforward(self, Q, K, V, mask=None): # Apply linear transformations and split heads # Q -> W_q Q + b Q = self.split_heads(self.W_q(Q)) K = self.split_heads(self.W_k(K)) V = self.split_heads(self.W_v(V)) # Perform scaled dot-product attention attn_output = self.scaled_dot_product_attention(Q, K, V, mask) # Combine heads and apply output transformation output = self.W_o(self.combine_heads(attn_output)) return output
split_heads() function reshapes the input x into the shape (batch_size, num_heads, seq_length, d_k). It enables the model to process multiple attention heads concurrently, allowing for parallel computation.
combine_heads() function combines the results back into a single tensor of shape (batch_size, seq_length, d_model). This prepares the result for further processing.
defforward(self, Q, K, V, mask=None)
Forward Method
defforward(self, Q, K, V, mask=None):
In the Forward layer, the input Q, K, V is first split into multiple layers, then passed through the linear layer, then into the scaled_dot_product_attention layer, and finally combined with the output.
2. Position Wise Feed Forward Layer
Figure-2 Feed Forward Layer (source: from paper)
Easily we write the corresponding code with reference to the formula: